
What are Data Feeds?
Data Feeds (formerly known as “Clickstream Data”) is a way to get atomic-level, batched data, out of Adobe Analytics. Businesses typically use Data Feeds for more complex analytical needs such as forecasting, clustering, machine learning, data products, and for combining with other data sources.
How does it work?
Once Adobe Analytics processes incoming data it stores it in its internal data warehouse at which point any active Data Feeds jobs are able to pick up newly processed data. The Data Feeds process then picks up the data, compresses it into a smaller archive, and sends out the data to your destination.
How can I get started?
If you have an IT resource or data engineering team they can help you set up an endpoint, otherwise, Adobe can also set up an FTP endpoint for you:
What are the configuration options?
| Option | Adobe Description | Miguel’s Notes |
|---|---|---|
| Name | The name of the data feed. Must be unique within the selected report suite, and can be up to 255 characters in length. | I recommend putting the Report Suite ID, interval, endpoint, and directory in the name. For example:reportsuitid_hourly_s3_bucketname |
| Report suites | The report suite the data feed is based on. If multiple data feeds are created for the same report suite, they must have different column definitions. Only source report suites support data feeds; virtual report suites are not supported. | Try to limit one report suite per data feed for easier troubleshooting unless you manage hundreds of report suites. |
| Email when complete | The email address to be notified when a feed finishes processing. The email address must be properly formatted. | I recommend sending it to a group email address that way team members can be added/removed without having to update the data feed configuration. Some customers also send it to a notification service like Amazon Simple Email Service (SES) to trigger actions. |
| Feed interval | Hourly feeds contain a single hour’s worth of data. Daily feeds contain a full day’s worth of data; they include data from midnight to midnight in the report suite’s time zone. | Depends on business requirements. Keep in mind that even hourly data can take a while to process and Adobe does not guarantee delivery within a given timeframe. However, in my experience, hourly files typically arrive 20-30 minutes after the time period wraps up. For tentpole events, be sure to work with your Adobe consultant or account manager so that processing can scale up accordingly. |
| Delay processing | Wait a given amount of time before processing a data feed file. A delay can be useful to give mobile implementations an opportunity for offline devices to come online and send data. It can also be used to accommodate your organization’s server-side processes in managing previously processed files. In most cases, no delay is needed. A feed can be delayed by up to 120 minutes. | Useful for offline tracking and other data importing implementations. |
| Start & end dates | The start date indicates the first date you want a data feed. Set this date in the past to immediately begin processing data feeds for historical data. Feeds continue processing until they reach the end date. The start and end dates are based on the report suite’s time zone. | |
| Continuous feed | This checkbox removes the end date, allowing a feed to run indefinitely. When a feed finishes processing historical data, a feed waits for data to finish collecting for a given hour or day. Once the current hour or day concludes, processing begins after the specified delay. | |
| Feed Type | FTP, SFTP, S3, Azure Blob | Try to avoid FTP as data is sent as plain-text (without encryption) |
| Host | Data feed data can be delivered to an Adobe or customer hosted FTP location. Requires an FTP host, username, and password. Use the path field to place feed files in a folder. Folders must already exist; feeds throw an error if the specified path does not exist. | |
| Path | n/a | Place at the root directory (leave blank) or enter a path to place data in a different directory |
| Username | Username for FTP or SFTP server | |
| Password | Password for FTP server | It is not recommended to use FTP as data is sent in plain-text, without encryption. |
| RSA Public Key / DSA Public Key | n/a | Cryptographic key needed to authenticate over SFTP. Use either RSA or DSA, not both. |
| Bucket/Container | n/a | For S3 and Azure blob only – the location to deliver the data to. Buckets/Containers are like folders. |
| Access Key | n/a | For S3 only – used to authenticate on S3. Think of it like a username. |
| Secret Key / Key | n/a | For S3 and Azure blob only – used to authenticate. Think of it like a password. |
| Account | n/a | For Azure blob only – the Azure account name |
| Compression Type | Gzip or Zip | Gzip is the standard file compression for Unix and Linux systems and is my recommendation for Pandas/Spark and virtually all data pipelines. Zip can be used for testing and one-offs. |
| Packaging Type | Single file outputs the hit_data.tsv file in a single, potentially massive file. Multiple files paginates your data into 2GB chunks (uncompressed). If multiple files is selected and uncompressed data for the reporting window is less than 2GB, one file is sent. Adobe recommends using multiple files for most data feeds. | For any type of production use or for large traffic volumes it is recommended to use multiple files. This is especially true for keeping data pipelines lean. |
| Manifest File | Whether or not Adobe should deliver a manifest file to the destination when no data is collected for a feed interval. If you select Manifest File, you’ll receive a manifest file similar to the following when no data is collected | I recommend the manifest file for production use to check for data integrity once you have taken delivery of the data. |
| Remove escaped characters | When collecting data, some characters (such as newlines) can cause issues. Check this box if you would like these characters removed from feed files. | Recommended in most use cases unless you have a special case. |
What is in a Data Feed?
In a Multiple File packaging with the manifest file option, you will receive the data, lookup files, and the manifest file.
For example:
| File | Description |
|---|---|
| 01-reportsuiteid_20210821-000000.tsv.gz | The data file. Contains hit-level data without any headers. Data files can contain over 1100 columns and millions of rows depending on your configuration and traffic volumes. Contents is a Tab Separated Values (TSV) type that is gzipped and encoded using ISO-8859-1. The “gz” extension stands for “Gzip” which is a data compression method. |
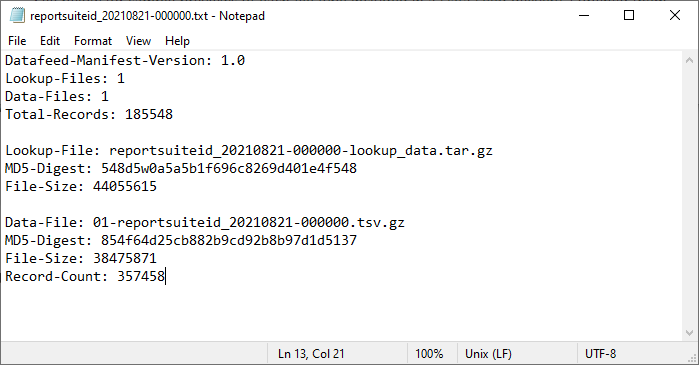
| reportsuiteid_20210821-000000.txt | The manifest file. Contains an inventory of what was delivered including MD5-Digests to check data integrity before you begin processing. |
| reportsuiteid_20210821-000000-lookup_data.tar.gz | Lookup files. A compressed archive containing multiple lookup files. The number of lookup files will vary depending on your configuration, and specific data being processed. browser_type.tsv browser.tsv color_depth.tsv column_headers.tsv connection_type.tsv country.tsv event.tsv javascript_version.tsv languages.tsv operating_systems.tsv plugins.tsv referrer_type.tsv resolution.tsv search_engines.tsv “tar” file extension indicates that multiple files have been combined or tarred into one, without compression. “gz” file extension indicates that a single file was compressed or gzipped. In linux and unix, the concept of consolidating (combining) and compressing (zipping) are separated out into two tasks. Compressing or gzipping can only be done on one file, thus multiple files need to be tarred first. |
See below for sample previews of each file type included in a Data Feed delivery. I opened them up in Excel for easy viewing. However, Excel is not recommended for data analysis since it cannot handle the scale and column types without manual tuning. For real production use it is recommended to use Pandas for one-offs and Spark for data pipelines.
Data File – 01-reportsuiteid_20210821-000000.tsv.gz
As mentioned in the description, this is the tab-separated values (TSV) file with our data. There will be many blank columns for dimensions that do not apply or are not set up for your report suite(s). Some columns here will be IDs that will need to be looked up against the lookup files.
See here for column definitions
Manifest File – reportsuiteid_20210821-000000.txt
Lookup File – column_headers.tsv
These are the column headers to the data file. When setting up the Data Feed and selecting “All Columns”, you can expect 1100-1300 columns.

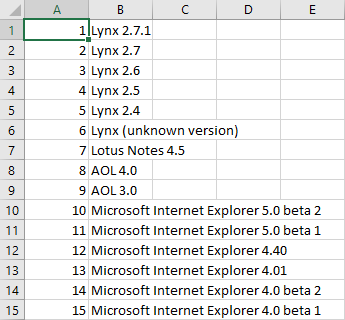
Lookup File – browser.tsv
The browsers lookup file will contain an ID and a browser name column. The list of browsers will continue to grow since new browser versions are being released daily by the many browser-developing companies.
This is the basic structure of a Data Feeds delivery whether it be hourly or daily. Depending on your traffic volumes and your data feeds configuration, you should be prepared to potentially receive gigabytes of compressed data per day. You can use microservices and pipeline orchestration tools like Apache Airflow to extract, transform, and load your data into Redshift/Aurora or Big Query. For smaller deployments, you can set up AWS Athena + Glue to query the data directly in S3 without having to load it into a database first, although this is not recommended for read/write heavy operations.