With all the talks about customer journeys and data storytelling, has anyone stopped to tell the story of an eVar? That’s my goal today, to walk you through the journey of an eVar.
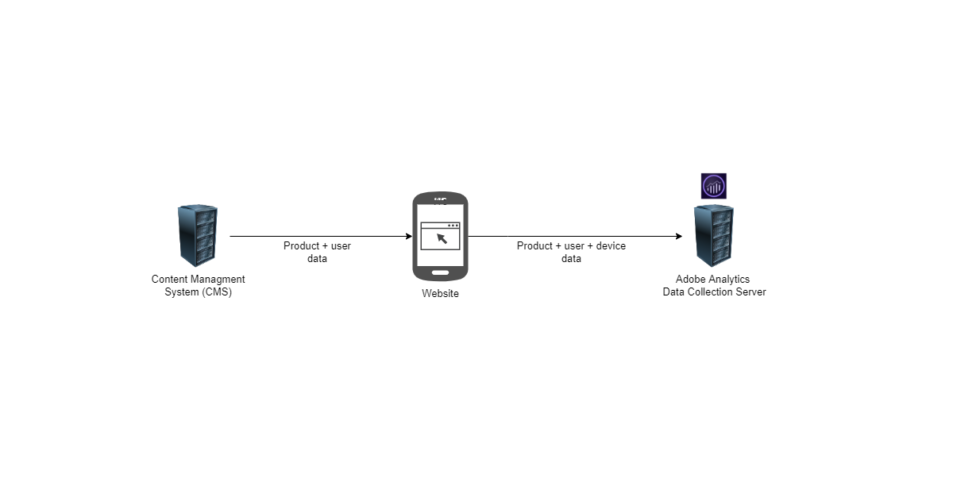
Let’s start by looking at a high-level view of what happens. For starters, we have a client that connects with multiple servers. These servers sometimes provide information and sometimes collect information. In our example above, we have a server that provides content data and another server that collects Adobe Analytics data.
Looking at it from left to right, you start to see the path of an eVar. Content management system or “CMS” data makes its way into the client browser and then gets shipped off to an Adobe Analytics data collection server. In its simplest form, this is one of the journeys that an eVar can take. However, in the real world, there are sometimes dozens of servers providing different services to the client/customer,
Client Request to CMS for User Data
Let’s zoom in a little on the left-hand side of the client.
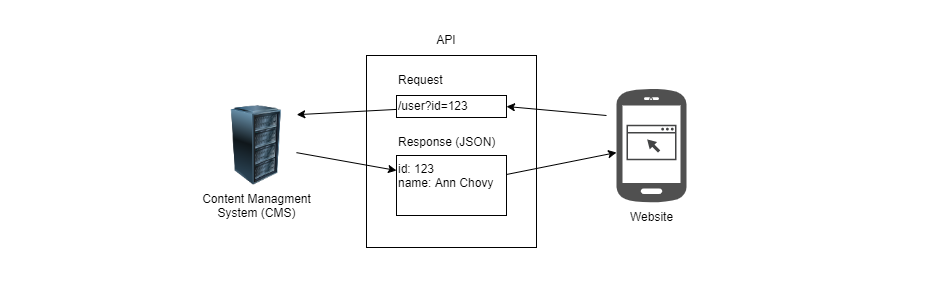
The image below shows that the client browser is requesting user data from the CMS. The initial request from the client hits the /user endpoint with the id=123 query parameter. The CMS then responds back with the same user ID and the name of the user. The client will then use the user name to display it back on the page as a greeting message – “Welcome Ann Chovy”.
The client browser makes these requests to the CMS via an API. An API or Application Program Interface is an agreement between two applications on how they can talk to each other. For example, the CMS API documentation will say something like “To request user data, send a GET request to /user with an id query string parameter”. The API documentation will spell out all the endpoints, how to send requests, and what to expect as a response. APIs are often developed internally within a company but can also be provided by a vendor.
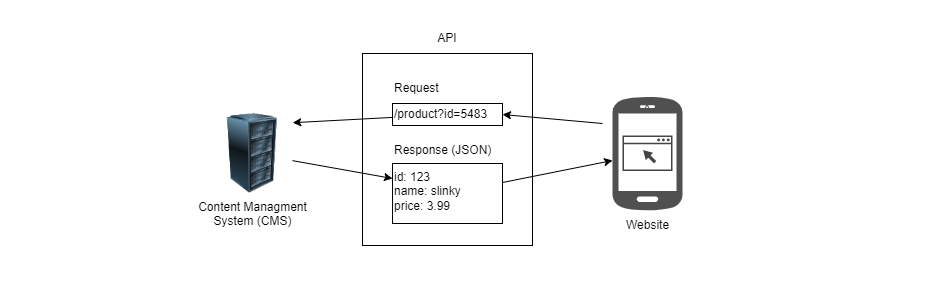
Below, we see a second request from the client browser to the CMS. This time, we are requesting product data. The product ID, name, and price will be displayed on the page and sent to Adobe Analytics for data collection.
Browser Data Transformations
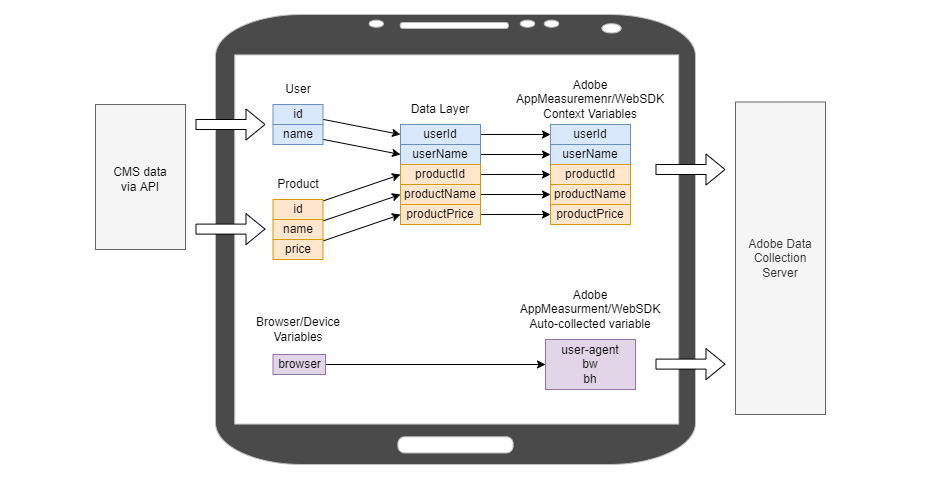
Up to this point, we have seen how data gets to the client browser, but we don’t know what happens at the browser before it gets shipped to the data collection server.
In the browser, we typically rename variables, concatenate, or create new variables depending on the business requirements. For example, we could take the user id variable and copy it into the data layer as userId. This simple renaming could be all that is needed.
Hashing and Data Privacy Transformations
For data privacy reasons, a business may have to hash all user IDs before they arrive at Adobe Analytics. The client could achieve this by using a tag manager to hash a variable. For example, the tag manager could hash User ID 123 into a665a45920422f9d417e4867efdc4fb8a04a1f3fff1fa07e998e86f7f7a27ae3 by applying a hash256 algorithm. Now, someone looking in Adobe Analytics would have no way of knowing the true user ID without a lookup key. This adds a privacy mask over the data stored in Adobe Analytics.
Data Standardization and Data Cleaning
Another common practice is standardizing and cleaning data before sending it to the data collection server. This is helpful for all data but particularly for user-inputted data. For example, we could lowercase the city a user may enter during checkout. Another example could be removing leading or trailing whitespaces or reserved characters.
Concatenations or Splitting
Sometimes, we may need to concatenate two variables before sending them to the data collection server. Similarly, we may need to split up a variable into multiple parts.
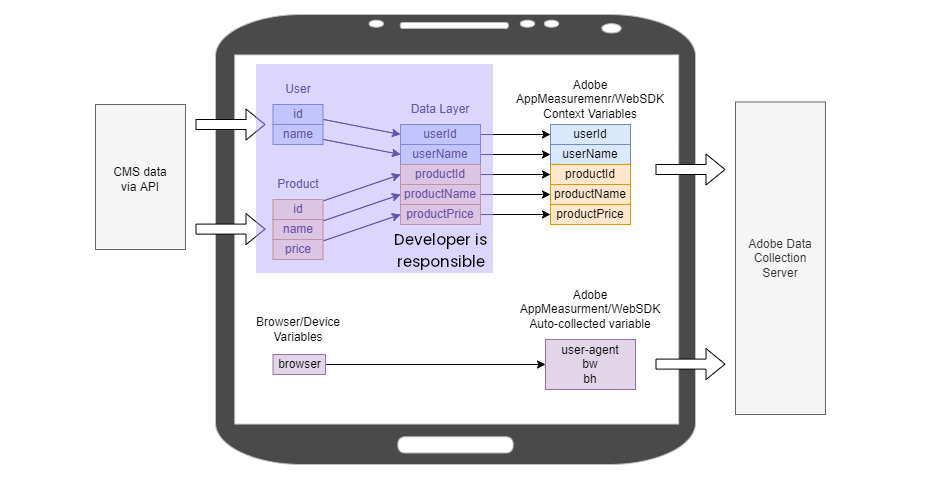
Developer Responsibilities
A developer or “front-end developer,” as they are sometimes referred to, is typically responsible for getting data into the browser and then into the data layer. In many cases, the developer already uses user and product data for UX purposes, so it is not a lot of extra work to make the same data available to the data layer, where the tag manager engineer can pick it up.
Another common developer responsibility is tying user actions to analytics events. For example, an organization may want to track product images that a user can scroll through – in this case, a developer is responsible for listening to user interactions and passing that information to analytics methods.
Ex: When a user clicks on the next product image, call _satellite.track("productImageView")
Tag Manager Engineer Responsibilities
A tag manager engineer is responsible for taking what is in the data layer, transforming it as needed, and feeding it into the tags that are on the page. For example, take userId, hash the value, then map it into s.eVar5.
A tag manager engineer may also need to set up event listeners and scrape the DOM for data, then send that event data to Adobe Analytics. For example, listen for clicks on “Add to Cart”, then scrape product ID from an element on the page, then trigger s.tl() analytics method. This is similar to the developer’s responsibility in the previous example. Generally, this type of work can fall into the developer or tag manager engineer domain depending on the company.
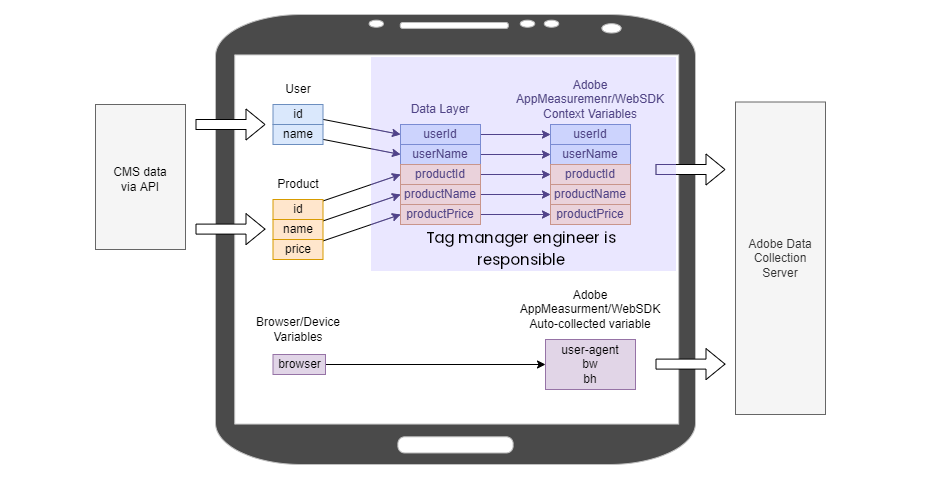
As a minor point, an analytics SDK like AppMeasurement.js or WebSDK also collects some data by default. Typically they collect things like browser dimensions, document title, and other environment-type of variables. A tag manager engineer can modify or enable/disable this type of tracking to some extent.
Adobe Analytics Processing and Transformations
Zooming into the Adobe Analytics data collection and data processing servers we see that there are even more transformations happening.
A data beacon as it arrives at an Adobe Analytics server may go through processing rule transformations. For example, the context variable productPrice may go through a processing rule where it is assigned to eVar4 and prop4. One caveat that Adobe Analytics engineers need to keep in mind is that context variables are not auto-assigned into eVars and props. For example, the context variable userName is present on the data beacon but is not mapped to any Adobe variable in processing rules so it is simply discarded.
Another pseudo transformation that happens is, in the case of context variables, the name of the context variable may not exactly match the evar or prop report name. For example, the context variable productName gets mapped into the product name (eVar3) report.
Additionally, there could be Vista Rules or Marketing Channel processing rules that transform the data further. There are also IP filters that could drop entire beacons which would affect the overall data that is being collected.
Lastly, the data ends up in an Analysis Workspace report, where it is ready for consumption.
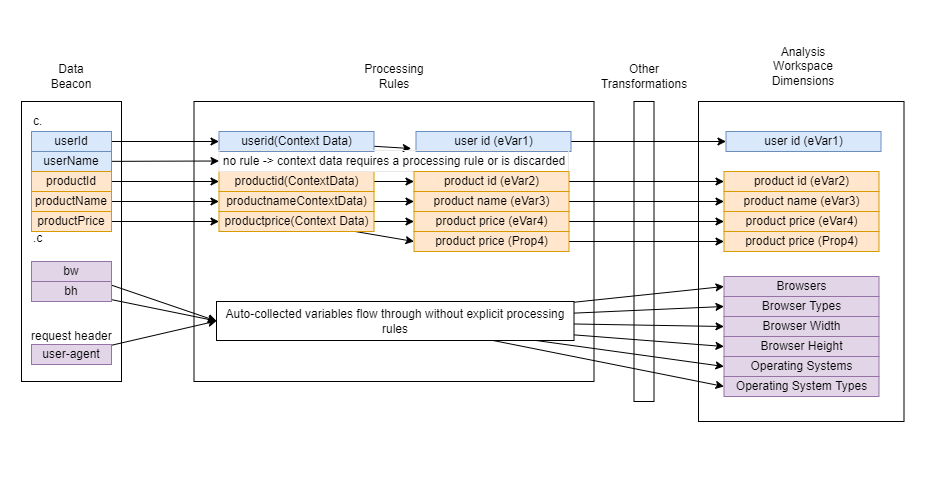
To recap, data originates from a content management system (CMS) or server, then travels to the client browser where it is stored in the data layer and may go through transformations before getting shipped off to Adobe Analytics where it can go through even more transformations, then finally ends up in a Workspace report.